Savant vs. DeepStream: What to Use, When, and Why
If you are considering NVIDIA hardware for video analytics, you will inevitably encounter several options: PyTorch (which many engineers already use for training), DeepStream, and Savant. We have already covered when PyTorch fits and when it does not — this article focuses on the relationship between DeepStream and Savant. The two cause confusion because they share the same underlying technology, both produce the same kind of output, and both run on the same hardware. So what is the difference, and when does it matter?
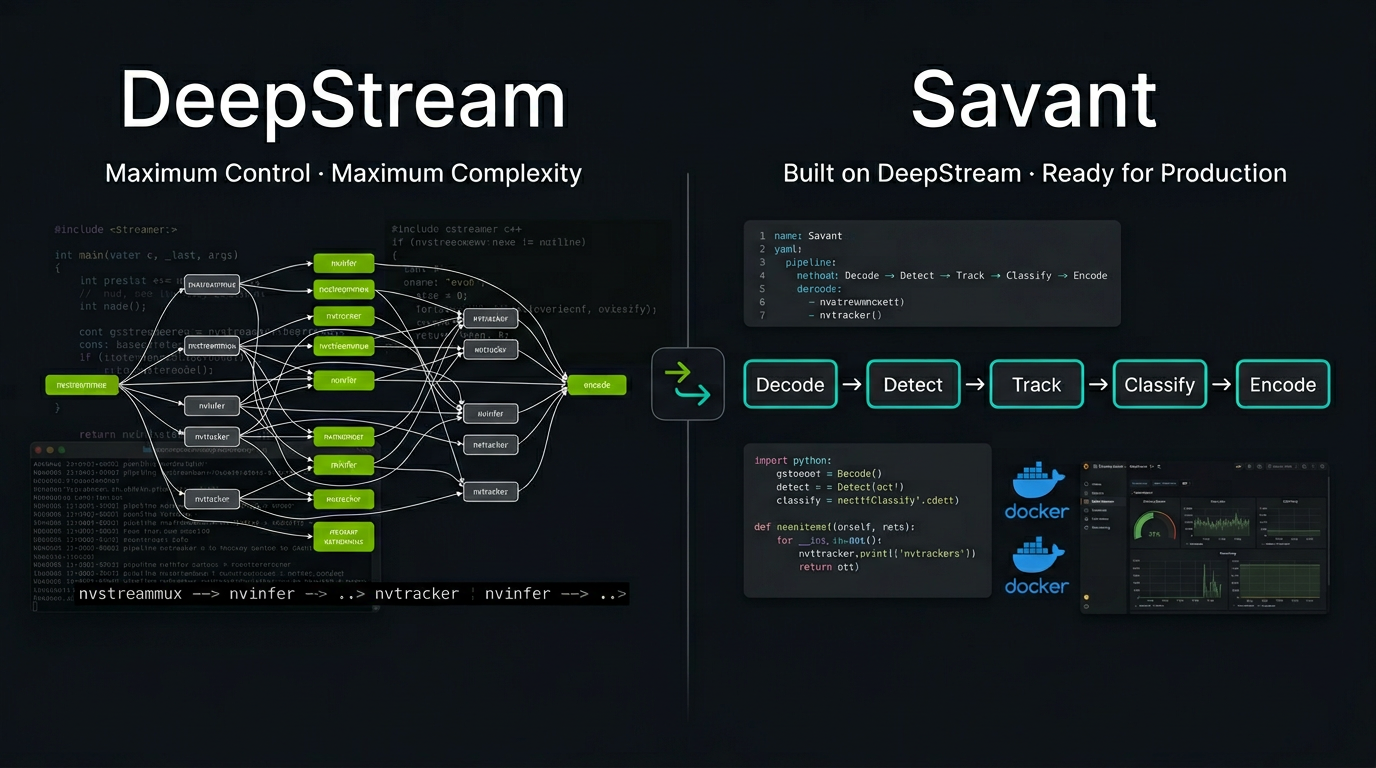
The short answer: DeepStream is NVIDIA’s low-level SDK that provides maximum control and performance. Savant is an open-source framework built on top of DeepStream that trades a small amount of raw throughput for a dramatically faster development cycle, production-ready tooling, and a Python-first programming model. The long answer is more nuanced, and the right choice depends on your team’s skills, your project’s constraints, and where you are in the development lifecycle.
What DeepStream Actually Is
NVIDIA DeepStream is a streaming analytics SDK built on GStreamer, the open-source multimedia framework. It provides a set of GStreamer plugins that leverage NVIDIA hardware: NVDEC for video decoding, TensorRT for inference, and NVENC for encoding. Frames flow through a GStreamer pipeline, staying in GPU memory from decode to encode, with precise control of data placement and affinity. That is the fundamental reason DeepStream outperforms approaches where data moves voluntarily between CPU and GPU RAM — the latter saturates PCIe bandwidth long before the GPU’s inference capacity is reached.
DeepStream is the recommended and most optimized technology for video analytics on NVIDIA platforms. It represents NVIDIA’s own best practices for utilizing their hardware to its full potential. In benchmarks, a well-tuned DeepStream pipeline consistently delivers the highest possible throughput for a given GPU.
The problem is getting there.
The DeepStream Developer Experience
DeepStream’s power comes at a cost that is not immediately apparent from NVIDIA’s documentation. Let us be candid about what building a production system on raw DeepStream entails.
GStreamer Is Mandatory
GStreamer is an event-driven, multi-threaded multimedia framework designed for media players and streaming servers. Its programming model is based on pipeline graphs where data flows through elements connected by pads, with behavior controlled by signals, callbacks, and custom plugins. It is a paradigm that even experienced C++ developers find challenging — and it is not what most ML engineers have ever encountered.
Every DeepStream application is a GStreamer application. Adding a model means configuring or writing a GStreamer plugin. Accessing inference results means attaching probe functions to GStreamer pads and traversing NvDsBatchMeta structures through nested C-style linked lists. Handling multiple video sources means understanding GStreamer’s streammux behavior, negotiation, and buffer management.
C++ Is the Primary Language
DeepStream’s native API is C/C++. There are Python bindings (pyds), but they are thin wrappers over the C API. Working with them still requires understanding GStreamer’s C-oriented object model (GObject), manual memory management patterns, and DeepStream’s metadata structures. The Python experience is far from what a PyTorch or scikit-learn developer would expect.
No Defined Architecture
DeepStream is an SDK — a collection of plugins and utilities. It does not define how your application should be structured, deployed, or monitored. It does not provide a streaming protocol, a deployment model, or an observability stack (except for the low-level profiling tool NVIDIA Nsight™ Systems). Those are your responsibility. For a research prototype, this is acceptable. For a production system processing 64 cameras in a data center with SLA requirements, it means building significant infrastructure around DeepStream before you ship anything.
What It Takes to Build and Extend
Building and extending a solution on raw DeepStream means living inside GStreamer’s programming model — and that model is where most of the difficulty concentrates:
- Debugging is opaque. GStreamer pipelines are multi-threaded by design: data flows through elements on different threads, controlled by internal schedulers. When something goes wrong — a frame is dropped, a model produces no output, a stream stalls — the failure is rarely local. A hung downstream element can back-pressure the entire graph, and the symptom surfaces far from the cause. Standard Python or C++ debugging techniques (breakpoints, stack traces) are of limited help because the relevant state is spread across GStreamer’s internal queues, pad buffers, and thread pools.
- Error messages are GStreamer’s, not yours. When a DeepStream pipeline fails, the errors you see are GStreamer errors:
not-negotiated,streaming stopped,internal data stream error. Mapping these back to your application logic — which model failed, which source caused the problem, which configuration is wrong — requires deep familiarity with both GStreamer internals and DeepStream’s plugin-specific behaviors. The learning curve here is not a one-time cost; each new failure mode requires a new investigation. - Metadata traversal is low-level and error-prone. Accessing inference results means walking
NvDsBatchMeta→NvDsFrameMeta→NvDsObjectMeta→NvDsClassifierMetathrough C-style linked lists. Each traversal requires correct pointer handling. A wrong cast or a missed NULL check produces a segfault, not a Python exception. Even with thepydsbindings, the API surface mirrors the C structures and offers no safety net. - Extending the pipeline is costly. Adding a new processing step — a custom postprocessor, a filtering stage, a metadata enrichment function — means either writing a GStreamer plugin in C/C++ or attaching a probe callback to a pad. Both approaches require understanding GStreamer’s threading model, buffer ownership rules, and event propagation. A change that would be a ten-line Python function in a higher-level framework becomes a multi-day effort involving GStreamer boilerplate, thread safety considerations, and integration testing against the pipeline graph.
- Reproducing issues is difficult. GStreamer’s asynchronous, event-driven nature means that pipeline behavior depends on timing, thread scheduling, and buffer availability. A bug that manifests under load or with a specific combination of sources may not appear in isolation. There is no built-in mechanism to capture and replay the exact pipeline state that led to a failure.
None of these are unsolvable for a team with deep GStreamer expertise. But they define the daily experience of building and extending a DeepStream application — and they are the primary reason that development timelines on raw DeepStream are measured in months, not weeks.
What Savant Adds
Savant is built on DeepStream. When a Savant pipeline processes video, it is DeepStream running the inference, DeepStream managing the GPU memory, and DeepStream’s plugins handling the decode/encode cycle. Savant does not replace DeepStream — it organizes it.
The relationship is comparable to Django and Python’s HTTP libraries, or Spring Boot and Java’s servlet API. You could build the same application without the framework, but the framework defines patterns, eliminates boilerplate, and provides the production machinery that would otherwise consume months of engineering.
Python-First, Not Python-Compatible
Savant’s API is designed for Python developers, not C++ developers using Python bindings. Pipeline logic is written in Python functions (PyFunc units) that receive structured metadata objects — not GStreamer probe callbacks with raw pointers. You work with detected objects, their attributes, tracking state, and frame metadata through a clean API. NumPy, OpenCV, CuPy, PyTorch, and any other Python library can be used directly in the processing chain.
The GStreamer layer is completely hidden. You never write a GStreamer pipeline string, never implement a GStreamer plugin, never deal with pad negotiation or signal handlers.
Declarative Pipeline Definition
A DeepStream pipeline is defined by constructing GStreamer elements in code, linking them, configuring properties, and attaching probes. A Savant pipeline is declared in YAML:
pipeline:
elements:
- element: nvinfer@detector
name: Primary
model:
format: onnx
model_file: yolov8m.onnx
precision: fp16
input:
shape: [3, 640, 640]
output:
num_detected_classes: 80
- element: nvinfer@attribute_model
name: Classifier
model:
format: onnx
model_file: resnet50.onnx
input:
object: Primary.person
The framework handles model conversion to TensorRT engines, batch construction, ROI extraction for secondary models, and metadata flow between stages. Adding a model is editing a YAML file, not writing a GStreamer plugin.
Streaming Protocol and API
Every Savant pipeline is, by default, an API-enabled service. It communicates with the outside world through a custom streaming protocol built on ZeroMQ and Protobuf. The protocol carries both video and metadata — including arbitrary user-defined attributes, IoT telemetry, GPS coordinates, or anything else your application needs.
Savant provides ready-to-use adapters for RTSP, USB cameras, video files, Kafka, Amazon KVS, and more. A Client SDK allows Python programs to inject frames and retrieve results with a few lines of code.
In raw DeepStream, you get video in and metadata out. There is no built-in mechanism to inject external data alongside video into the pipeline, no standard protocol for inter-service communication, and no adapter ecosystem.
Production-Ready Architecture Without Building It Yourself
To deliver a production-ready video analytics system, you need more than inference. You need containerization, observability, dynamic reconfiguration, health management, and a data transport layer. With raw DeepStream, every one of these is a separate engineering project. Savant provides them out of the box:
- Containerized deployment. Every pipeline and adapter runs in a separate Docker container. Shipping means writing a
docker-compose.ymlor a Kubernetes manifest — not building a custom deployment harness. - OpenTelemetry. Tracing is built in and propagated across services via the streaming protocol. Frame-level traces show exactly where time is spent — from adapter ingestion through every pipeline stage to output. You do not need to instrument the pipeline yourself.
- Prometheus metrics. Stage latency, throughput, queue depths, and custom metrics are exported without additional integration work.
- Dynamic configuration via etcd. Pipeline parameters — confidence thresholds, ROI zones, processing flags — can be changed without restarting the pipeline. etcd integration supports X.509 authentication. You do not need to build a configuration management layer.
- REST API. Health checks and shutdown control are built in — no need to design a management interface.
- Dynamic sources. Adding and removing video streams does not require pipeline restarts or custom GStreamer manipulation. Source resilience and reconnection logic are handled by the framework, not your code.
With raw DeepStream, each of these is weeks of engineering effort that has nothing to do with computer vision — it is plumbing. Savant eliminates that work so your team can focus on the models, the business logic, and the domain-specific behavior that actually differentiates your product.
Developer Tooling
- DevServer with hot reload. Modify a Python processing function, save, and the pipeline reloads in seconds — without rebuilding a container or restarting GStreamer.
- Client SDK. Send frames to the pipeline and receive results from your IDE, a Jupyter notebook, or an integration test.
- Docker-based development. Develop locally or remotely (including directly on a Jetson device) from VS Code or PyCharm. Zero local configuration — everything runs inside containers.
- OpenCV CUDA integration. Access DeepStream’s GPU-resident frames with OpenCV CUDA operations — crop, resize, transform, draw — without downloading to CPU memory. This is a capability that raw DeepStream does not expose through any high-level API.
Edge-to-Data-Center Convergence
A Savant pipeline runs without code changes on Jetson Orin (edge), GeForce desktop GPUs (development), and data center accelerators (T4, A10, L40, H100). The same Docker image, the same YAML configuration, the same Python code. A less powerful device delivers lower throughput, but the pipeline is identical.
More importantly, Savant enables hybrid architectures where part of the processing runs on edge devices and part runs in the data center. The ZeroMQ streaming protocol connects them, and the framework provides the routing, buffering, and fan-out/fan-in services to orchestrate the flow. Building this kind of distributed architecture on raw DeepStream means designing and implementing the inter-service communication layer from scratch.
What You Give Up
Savant is not a zero-cost abstraction. Being transparent about the trade-offs is important.
Raw Performance
Savant delivers approximately 80–90% of the throughput of a hand-tuned DeepStream pipeline. The gap comes from the framework’s overhead: Python function dispatch, metadata management, protocol serialization, and the generality of handling diverse pipeline topologies. For most applications, this is an excellent trade-off — you get 80–90% of the performance with perhaps 20% of the development time. For applications where squeezing the absolute last 10% of throughput from the hardware is a commercial requirement, raw DeepStream (or even lower-level NVIDIA libraries) may be necessary.
Low-Level Control
Savant deliberately hides GStreamer. This simplifies development enormously, but it also means you cannot easily reach into the GStreamer layer to implement highly specialized behaviors — custom buffer pool management, exotic element configurations, or direct manipulation of GStreamer’s scheduling. If your use case requires this level of control, you need DeepStream.
NVIDIA Lock-In
This applies to both Savant and DeepStream equally: both are NVIDIA-only. If your deployment target includes AMD GPUs, Intel accelerators, or non-GPU edge devices, neither tool applies. (For NVIDIA hardware specifically, this is rarely a concern — the hardware ecosystem is mature and broadly deployed.)
Decision Framework
Choose Raw DeepStream When
- Maximum throughput is a hard commercial requirement. If 80–90% of peak performance is not enough and you need every last frame per second, DeepStream gives you the control to get there.
- Your team has deep GStreamer and C++ expertise. If your engineers are comfortable writing GStreamer plugins, managing pad negotiations, and debugging multi-threaded pipeline graphs, DeepStream’s complexity is manageable and the performance ceiling is higher.
- C++ is required for compliance or integration reasons. Some regulated industries mandate specific languages or binary-level integration with existing C++ systems.
- You need a GStreamer element that Savant does not expose. DeepStream has a large catalog of GStreamer plugins; Savant exposes the most commonly used ones but not all.
Choose Savant When
- Your team consists of ML/CV engineers, not GStreamer specialists. If your developers are proficient in Python and PyTorch but have never touched GStreamer, Savant removes the steepest part of the learning curve entirely.
- Development speed matters. Savant’s declarative pipelines, hot reload, and Client SDK compress the development cycle from weeks to days. If time-to-market is a factor, this matters.
- You need to deliver a production-ready system, not just a pipeline. OpenTelemetry, Prometheus, etcd, health checks, dynamic sources, containerized deployment — all built in. Building this on raw DeepStream is months of additional engineering that has nothing to do with your models or domain logic.
- Your system processes multiple live video streams. Savant’s adapter model, dynamic source management, and streaming protocol handle the complexity of multi-camera systems — complexity you would otherwise engineer yourself.
- You need edge-to-cloud or hybrid architectures. Savant’s streaming protocol and service infrastructure (Router, Meta-merge) provide the distributed processing layer that you would otherwise have to design and build from scratch.
- You want OpenCV CUDA on GPU-resident frames. Savant’s OpenCV CUDA integration provides something that raw DeepStream does not offer through any high-level API — the ability to perform arbitrary OpenCV operations on frames without leaving GPU memory.
- 80–90% of peak performance is acceptable. For the vast majority of real-world deployments, this is more than sufficient.
Use Both When
- Prototyping in Savant, optimizing critical paths in DeepStream. Start with Savant for rapid iteration, identify the bottleneck, and rewrite only that component as a custom DeepStream plugin if needed.
- Evaluating NVIDIA’s video analytics stack. Savant is the fastest way to get a working pipeline on DeepStream without investing weeks in GStreamer education. If you later determine you need raw DeepStream, the architectural knowledge transfers.
A Concrete Example
Consider a traffic monitoring system: 16 RTSP cameras, vehicle detection with YOLOv8, license plate recognition, make/model classification, and results materialized to a database with augmented video streams delivered to a monitoring dashboard.
With raw DeepStream, your team would need to engineer:
- A GStreamer pipeline (C++ or Python bindings) assembling
nvstreammux,nvinfer(×3 models),nvtracker,nvvideoconvert,nvosd, andnvv4l2h264encelements. - Probe functions to extract metadata from
NvDsBatchMetastructures. - RTSP reconnection and watchdog logic around GStreamer’s
rtspsrc. - A data transport layer for database writes.
- An augmented stream delivery service.
- Docker images, deployment manifests, and a CI/CD pipeline.
- A monitoring and observability integration (Prometheus, Grafana, or custom).
- Dynamic source management logic (adding/removing cameras without pipeline restarts).
Estimated engineering effort for an experienced DeepStream developer: 4–8 weeks.
With Savant, you would:
- Write a YAML pipeline declaring the three models and their input/output relationships.
- Write Python
PyFuncfunctions for post-processing logic (plate text extraction, make/model aggregation). - Configure RTSP source adapters (built-in, handles reconnection).
- Configure a sink adapter for database writes (or use the Client SDK).
- Configure a video output adapter for the monitoring dashboard.
docker-compose up.
OpenTelemetry, Prometheus, dynamic source management, and etcd configuration require zero additional engineering — they are part of the framework. Estimated effort for an ML engineer with no prior DeepStream/Savant experience is up to 1 week.
The resulting system runs at approximately 80–90% of what the raw DeepStream implementation would achieve. For 16 cameras at 30 FPS each (480 FPS total), this difference is unlikely to matter — both approaches will comfortably handle the load on a single modern GPU.
Summary
| Dimension | DeepStream | Savant |
|---|---|---|
| Nature | SDK (GStreamer plugins) | Framework (built on DeepStream) |
| Language | C++ primary, Python bindings | Python-first |
| Pipeline definition | GStreamer pipeline strings / C++ | Declarative YAML |
| Learning curve | Very steep (GStreamer + NVIDIA specifics) | Moderate (Python + YAML) |
| Raw performance | 100% (reference) | ~80–90% |
| Model integration | Manual plugin configuration | Automatic from ONNX |
| Deployment model | DIY | Containerized, Docker/K8s native |
| Observability | DIY | OpenTelemetry + Prometheus built-in |
| Streaming protocol | None (DIY) | ZeroMQ + Protobuf, with adapters |
| Dynamic sources | Manual GStreamer manipulation | Built-in, with auto-recovery |
| Runtime config | DIY | etcd with X.509 auth |
| GPU frame access | Low-level NvBufSurface API | OpenCV CUDA integration |
| Edge ↔ data center | Requires adaptation per platform | Same pipeline, no code changes |
| Developer tooling | Minimal | DevServer, Client SDK, hot reload |
| Target developer | C++/GStreamer video engineer | Python CV/ML engineer |
DeepStream is the engine. Savant is the vehicle built around it. Both get you to the destination; the question is how much of the car you want to assemble yourself.
For a broader comparison of the computer vision technology landscape — including PyTorch, OpenCV, Triton, and others — see Choosing the Technology for a Computer Vision Product in 2025. For Savant vs. PyTorch specifically, see Savant vs. PyTorch: Purpose, Architecture, and When to Use Each.